
Reinforcement Learning is about learning to make good decisions under uncertainty. It's based on the reward Hypothesis which says:
That all of what we mean by goals and purposes can be well thought of as maximization of the expected value of the cumulative sum of a received scalar signal (reward).
This can be seen as an Optimization problem where our aim is to cumulate as much reward as possible (while learning how the world works) i.e goal is to find an optimal way to make decisions
Mathematically goal is to maximize the expected sum of discounted rewards and everything happens in a MDP setting.
1. Generalisation
Goal of the RL(and exploration) algorithm is to perform well across a family of environments
- “Generalizing between tasks remains difficult for state-of-the-art deep reinforcement
learning (RL) algorithms. Although trained agents can solve complex tasks, they struggle to transfer their experience to new environments. Agents that have mastered ten levels in a video game often fail catastrophically when first encountering the eleventh. Humans can seamlessly generalize across such similar tasks, but this ability is largely absent in RL agents. In short, agents become overly specialized to the environments encountered during training”
- if we don’t generalizations we can’t solve problems of scale, we need exploration with generalization” — ian osbond
2. Exploration vs Exploitation
How can an agent decide whether to attempt new behaviours (to discover ones with higher reward) or continue to do the best thing it knows so far? or Given a long-lived agent (or long-running learning algorithm), how to
balance exploration and exploitation to maximize long-term rewards ?
This is know as the Exploration vs Exploitation which has been studied for about 100 years and still remains unsolved in full RL settings.
Exploration is about Sample efficient(or smart) data collection — Learn efficiently and reliably. Combining generalisation with exploration(below) is an active area of research e.g see Generalisation and Exploration via randomized Value functions.
An interesting question to ask here is:
Can we Build a rigorous framework for example rooted in information theory for solving MDPs with model uncertainty, One which will helps us reason about the information gain as we visit new states?
3. Credit assignment
The Structure of RL looks at one more problem which is known as credit assignment. Its important that we have to consider effects of our actions beyond a single timestep. i.e How can an agent discover high-reward strategies that require a temporally extended sequence of complex behaviours that, individually, are not rewarding?
- “RL researchers (including ourselves) have generally believed that long time horizons would require fundamentally new advances, such as hierarchical reinforcement learning. Our results suggest that we haven’t been giving today’s algorithms enough credit — at least when they’re run at sufficient scale and with a reasonable way of exploring.” — OpenAI
An efficient RL agent must address these above challenges simultaneously.
To summarize we want algorithms that perform optimization, handle delayed consequences, perform intelligent exploration of the environment and generalize well outside of the trained environments. And do all of this statistically and computationally efficiently.
Now that we understand the problem, lets look at the solutions. One approach is to compute the value function.
A value function is an estimate of expected cumulative future reward, usually as a function of state or state-action pair. The reward may be discounted, with lesser weight being given to delayed reward, or it may be cumulative only within individual episodes of interaction with the environment. Finally, in the average-reward case, the values are all relative to the mean reward received when following the current policy.
The value-function hypothesis
all efficient methods for solving sequential decision-making problems compute, as an intermediate step, an estimate for each state of the long-term cumulative reward that follows that state (a value function). People are eternally proposing that value functions aren’t necessary, that policies can be found directly, as in “policy search” methods (don’t ask me what this means), but in the end the systems that perform the best always use values. And not just relative values (of actions from each state, which are essentially a policy), but absolute values giving an genuine absolute estimate of the expected cumulative future reward.

Given a policy we want to compute the expected return from a given state by computing the value function the simple idea of monte-carlo is that we compute the mean return for many episodes and keep track of the number of times that state is visited using the expected law of large numbers <br><br> and we don't wait till the end — we update step by step(a little bit) in the direction of the error i.e we update the value function by computing the difference between the estimated value function and the actual return at the end of each episode
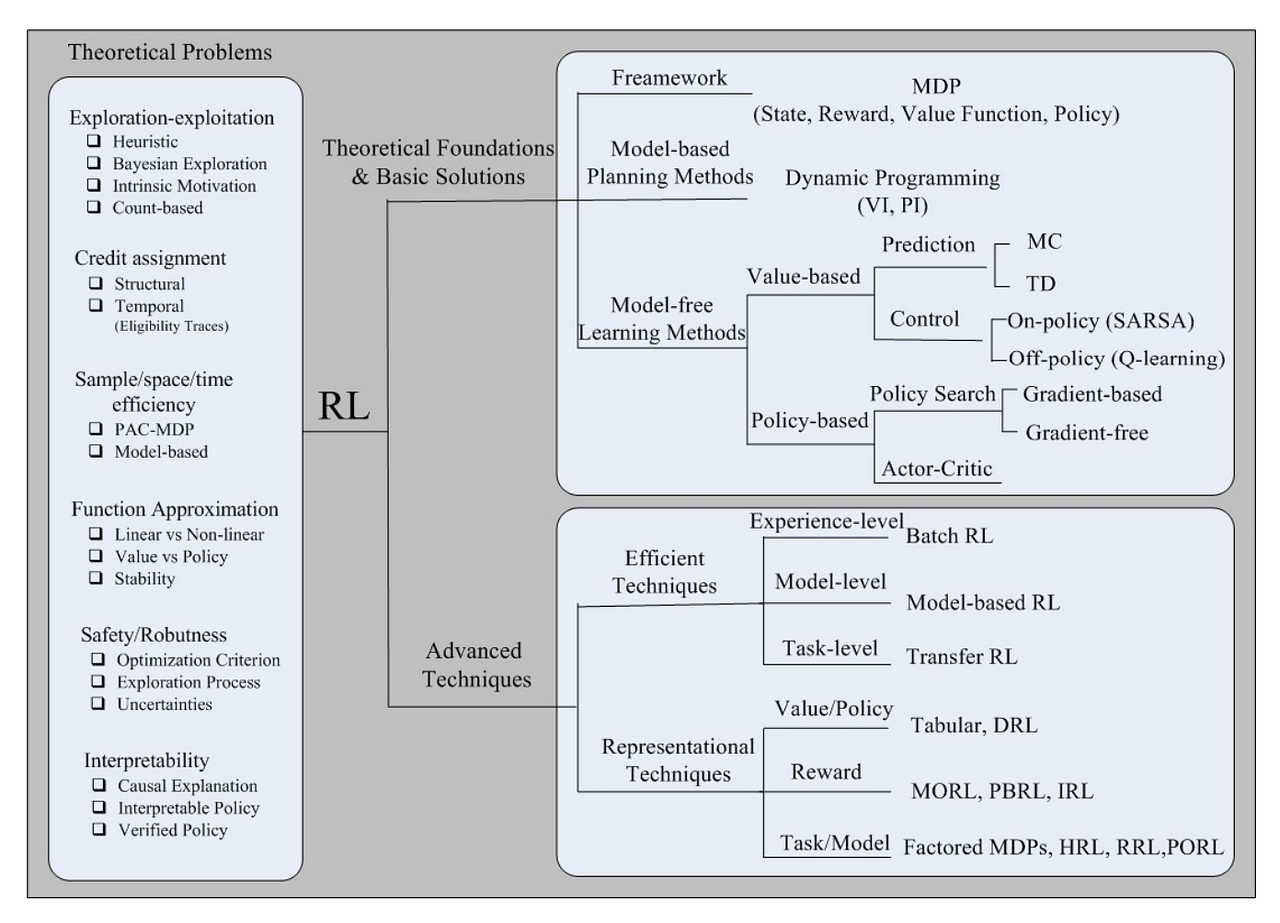
Value function isn’t the only way to solve the RL problem. We have 2 other approaches as well which we will discuss in coming posts, namely, model-based and policy-based. See figure below for the big-picture view.
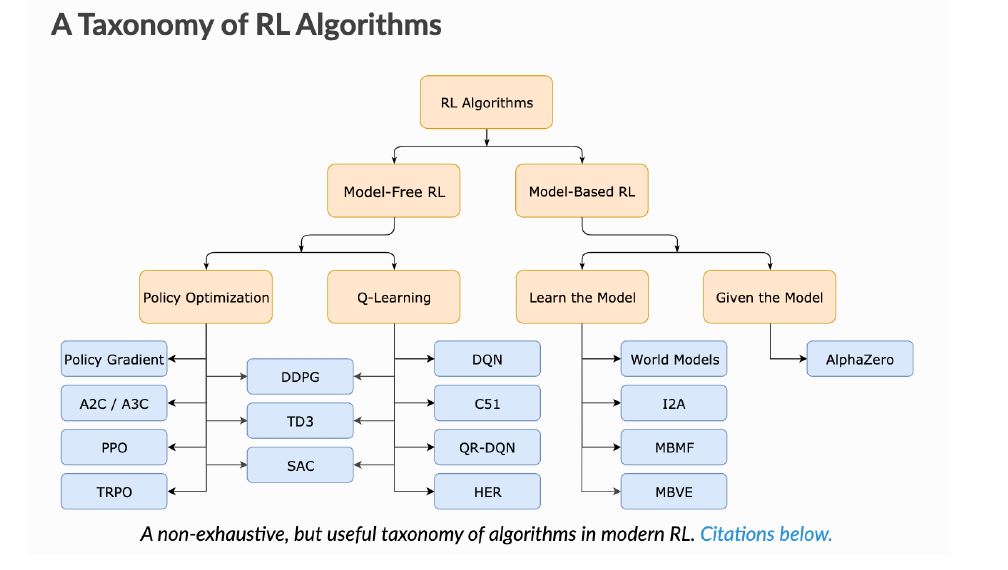
We note that this is not a solved problem:
“Design Algorithms that have generalisation and sample efficiency in learning to make complex decisions in complex environments” — Wen Sun
Disclaimer: I blog mainly to document my learning. I appolgize if I don’t provide all the references and borrow sentences as is.
[1] arxiv.org/pdf/1908.03568.pdf
[2] Deep Exploration via Randomized Value Functions: stanford.edu/class/msande338/rvf.pdf