

Process analytics involves a sophisticated layer of data analytics built over the traditional notion of process mining. Past execution histories available to us in process logs, annotated with rich descriptions of the contexts in which these processes were executed, can provide useful guidance in answering questions like:
How do we determine, for a partially executed process instance, what
the best suffix is for a task sequence (sequence of tasks), which, if executed,
will likely lead to desirable performance characteristics?
Flexible execution of business process instances entails multiple critical decisions involving various actors and objects, which can have a major impact process performance and achieving desired process outcomes. These decisions therefore require careful attention, as sub-optimal decisions during process execution, can lead to cost overruns, missed deadlines and the risk of failure. While the problem of predicting the behavior of a given process instance has been studied extensively, leveraging these predictions to support operational decision-making remains a challenge.
In this project, wedesigned a machine learning-based process-aware suffix recommender system that can addresses this challenge. Our work explores the latest advances in deep learning and leverages a novel neural network architecture, namely Write–Protected Dual Controller Memory–Augmented Neural Network(DCw-MANN), for generating suffix recommendations that lead to opitmal outcomes.
Our goal in this project is to derive a process–agnostic machinery for learning to predict the future given a partially executed process instance, with minimal domain knowledge. Based on these predictions, an effective model should be expressive enough to capture all variations in the process execution, and at the same time be compact enough to learn robustly from the given data. Keeping this in mind we investigate the applicability of Memory–Augmented Neural Networks (MANN) for tackling a number of process analytics problems and compare to other state-of-the-art methods.
Datasets
Process analytics leverages a range of data, including, but not limited to process logs, event logs , provisioning logs, decision logs and process context and answers queries that have a number of real-world and applications particularly related to prescriptive analytics such as resource optimisation and instance prioritization.
– Helpdesk: This log contains events from a ticketing management process of the help desk of an Italian software company. The process consists of 9 activities, and all cases start with the insertion of a new ticket into the ticketing management system. Each case ends when the issue is resolved and the ticket is closed. This log contains around 3,804 cases and 13,710 events, which results in about 14K training and 4K testing samples.
– Moodle Dataset: This dataset has been created from Moodle’s(e-learning platform) issue tracking system. The issue tracking system collects bug reports and allows developers to track the bug resolution process as an issue goes through various development stages. The log contains 10,219 complete processes in total with the number of events in each process ranging from 4 to 23. The preprocessing procedure results in about 32K training prefix/suffix sequences and 8K prefix/suffix sequences. The number of event codes in Moodle dataset is 23.
– IT incident management Dataset: This is an anonlymised data set extracted from incident management system supporting an enterprise resource planning (ERP) application. It contains 16,000 tickets(process instances) of IT incident management processes. The log contains the life cycle of a ticket. The ticket is opened by a customer. It is acknowledged typically by a team lead, then it gets assigned to a person working on it and after some analysis and other changes, it gets closed. The group that solved the ticket might not correctly resolve the issue. The log contains the name of the last group that solved the ticket. After splitting, the Incident Mgmt. dataset has about 26K training and 6.5K prefix/suffix sequences. This dataset has 32 unique type of event codes.
Pre-Processing:
We train DeepProcess in this mode by offering as positive examples sets of operationally similar process instances that performed well. DeepProcess learns a model that deems these to be proximal. By way of negative examples, we offer operationally similar instances that performed poorly. The metric learnt by DeepProcess sets these instances at great distances apart from each other. Once trained, DeepProcess will be able to retrieve the top-k proximal instances to an input process instance (even a partially executed one). Depending on the richness of the representation of process instances, we can now answer a variety of questions such as the following:
Moodle dataset contains 10219 complete processes in total with the number of events in each process ranging from 4 to 23. Meanwhile, there are 2073 processes of length 5 to 24 in the Financial log dataset. We randomly divide both datasets into 80% for training and 20% for testing. Then, we continue splitting each process in the training and test sets into prefix sequence an suffix sequence such that the minimum prefix length is 4. Note that one process can be split many times. This procedure results in about 32K training prefix/suffix sequences and 8K prefix/suffix sequences for the Moodle dataset. For the Financial Log dataset, these numbers are approximately 4200 and 1000, respectively.
Next, we take each of these datasets and we split the logs into Positive and Negative instances and only train our models using Positive examples. In Moodle dataset we filter by apply a couple of pre-conditions such that each instance should have have at least four distinct states 1 and no more than 25 state changes. Negative examples are chosen with the assumption that bad process instances would shift states back and forth a lot (e.g., issue being reopened multiple times is a bad instance). Hence if more than 25 state changes occur for a given issueID then it would be labelled as a bad instance. Similarly for BPI2012 financial log data we filter cases based on running time.
| Duration: | % of cases |
| Max Duration: 1 day 19 hours | ~55% cases (Good Example Set) |
| Min Duration: 1 day 19 hours Max Duration: 138 days | ~ 45% cases (bad Performance Set) |
Raw dataset contains about 13,087 cases. Cases that started in 2012 were filtered out(about 49 percent because they are not likely to finish. Next we did performance filtering using total time duration for each case. Cases with a maximum duration of 1 day 19 hours are considered good instances while rest of them are labelled as bad performing instances.
Modeling - Memory Augmented Neural Networks
Recent advances in neural network architectures and learning algorithms have led to the popularization of ‘deep learning’ methods. Deep Learning methods are particularly good at discovering intricate structure and robust representations from large quantities of raw data thus significantly reducing the need to handcraft features which is usually required when using traditional machine learning techniques. Recurrent neural nets, especially the Long Short-Term Memory (LSTM) have brought about breakthroughs in solving complex sequence modelling tasks in various domains such video understanding, speech recognition and natural language processing. While LSTM can theoretically deal with long event sequences, the long-term dependencies between distant events in a process get diffused into the memory vector. A more expressive process model would allow storing and retrieval of intermediate process states in a long-term memory. This is akin to the capability of a trainable Turing machine. Closest to a Turing machine is a recent network known as Differential Neural Computer (DCN). The key behind these architectures is that all memory operations, including addressing, reading and writing are differentiable. This enables end-to end gradient-based training.
We introduce two key modifications to the default DNC architecture: (i) sepa-
rating the encoding phase and decoding phase, resulting in dual controllers; (ii)
implementing a write-protected policy for memory during the decoding phase.
Our proposed architecture enables decision support for partially executed pro-
cess instances in order to support process users and reduce the overall risk
associated with negative or sub-optimal outcomes. We evaluate the effective-
ness of our approach on three world datasets for predictive monitoring and
generating suffix recommendations that lead to optimal outcomes.
Results:
Next activity and time-to-event prediction

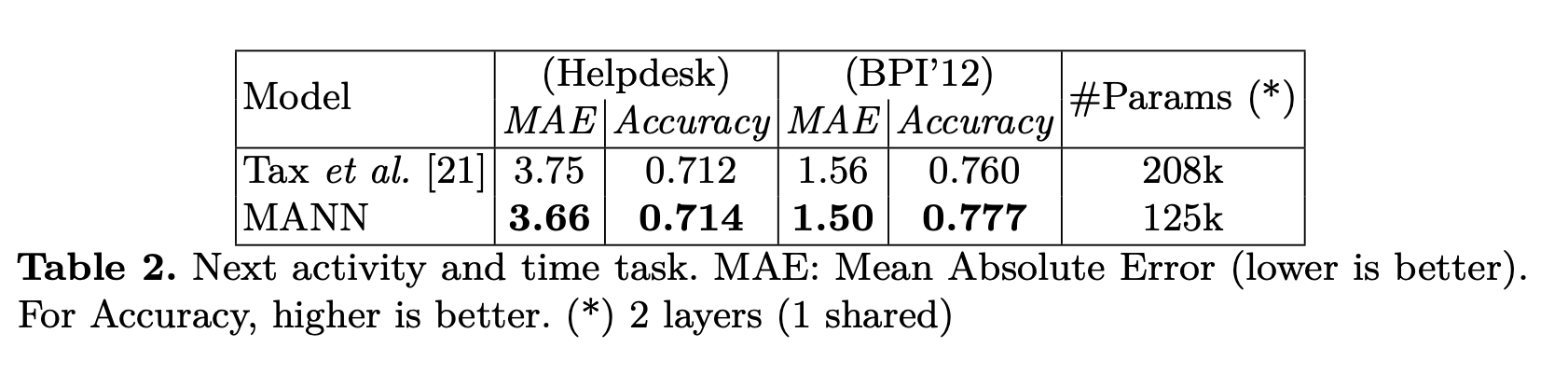
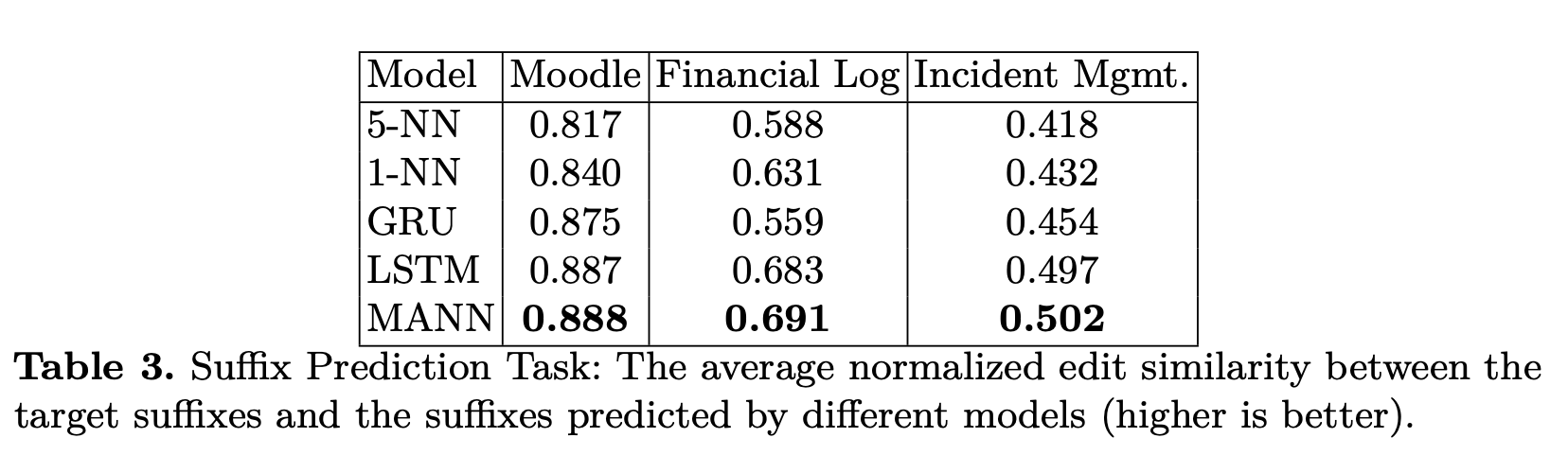
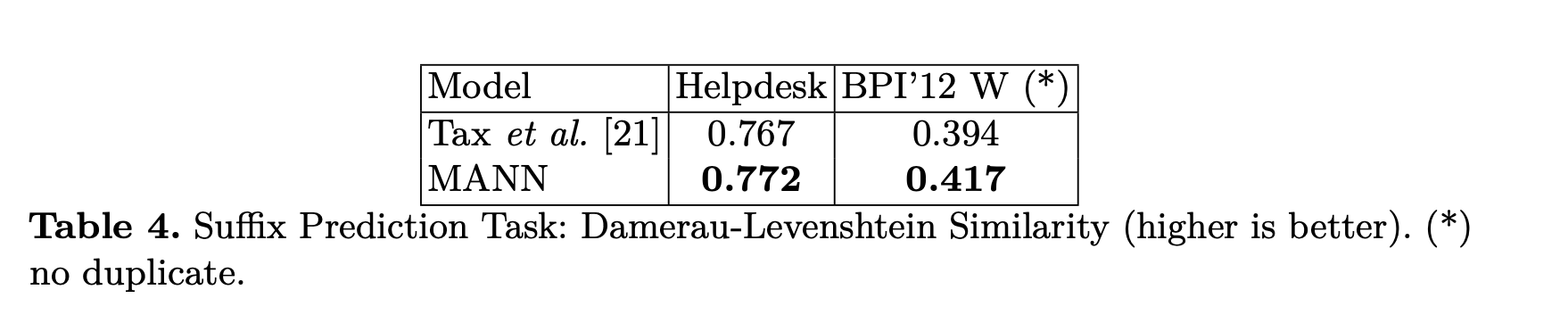
Conclusion:
Predicting undesirable events during the execution of a business process instance provides the process participants with an opportunity to intervene and keep the process aligned with its goals. Our work offers a promising path towards building MANN based predictive monitoring and process-aware recommender systems that have the ability to leverage historical event log data. Read the complete paper here.