
In today’s data-driven world, data has become the lifeblood of many successful organizations. Building Data-Centric AI solutions means that data strategy needs to be front, right and center. For most organizations, storing, analyzing, and deriving accurate insights from massive data volumes remains a key challenge. Building a strong data infrastructure, internal processes, and data pipelines is critical for implementing various data-driven solutions. In this post, we’ll discuss some strategies for organizations to harness the power of data.
Prof. Peter Norvig, who was previously the director of Google Search, highlights a common misconception in the following quote:
“Since ML algorithms and optimization are talked about more in literature and media, it is common for people to assume that they play larger roles than they do in the actual implementation process. … Optimizing an ML algorithm takes much less relative effort, but collecting data, building infrastructure, and integration each take much more work. The differences between expectations and reality are profound”.
Many leaders still believe that machine learning (ML) algorithms and optimization are the primary components of successful AI implementation. In reality, data collection, infrastructure building, and integration demand much more effort. To achieve success in data science, it’s crucial to lay a solid foundation by focusing on building the right data infrastructure and then establishing key data engineering processes that can drive the data-intensive solutions. This is closely related to the idea of the data science hierarchy of needs, where success in the upper half of the pyramid means first doing a good job with laying the foundations.

For implementing ML-based solutions, organizations face a number of challenges in practice. The first challenge organizations must tackle is that of sampling noise and bias, ensuring that the training data is representative of what is needed for solving the machine learning (ML) task at hand and contains relevant features. Data availability broadly translates to having the right quality and quantity, which helps build the correct feature set. Data needs vary based on the type of AI project. For example, the requirements for a project building a classification system will be different from one providing recommendations or rankings to customers. This requires organizations to be strategic about utilizing existing and new data sources for building, deploying, and operationalizing AI solutions at scale. Specifically, before starting each project, we need to formulate a strategy that will be useful for leveraging existing and new data sources needed to seamlessly build, deploy, and operate AI-based solutions at scale. To ensure this, we must:
1. Confirm data availability and build the required data infrastructure for each identified project.
2. Ensure that the datasets for the required features are available and meet the desired quality requirements.
3. Verify that there are enough historical data samples available in those datasets.
Dealing with Limited data Scenarios
AI thrives on large-scale computer resources, data, and efficient algorithms. Without these elements, AI initiatives can fail. Building useful AI systems can be achieved with varying amounts of data, from as few as 100 data points to massive ‘big data’ sets. However, obtaining more data is always beneficial. Mature organizations often employ sophisticated, multi-year data acquisition strategies tailored to their specific industry and situation. For instance, companies like Google and Baidu offer numerous free products to gather data that can be monetized in other ways. However, training data is often scarce for many valuable ML tasks, with 75% of the challenge in ML being the creation of the right dataset.
Building high-quality models that yield accurate predictions requires considerable effort, especially in specialized domains such as medical imaging. In healthcare, for example, tasks might involve analyzing radiology images to identify different forms of cancer or labeling a patient’s prognosis. These efforts become much more challenging as they require the involvement of specialists.
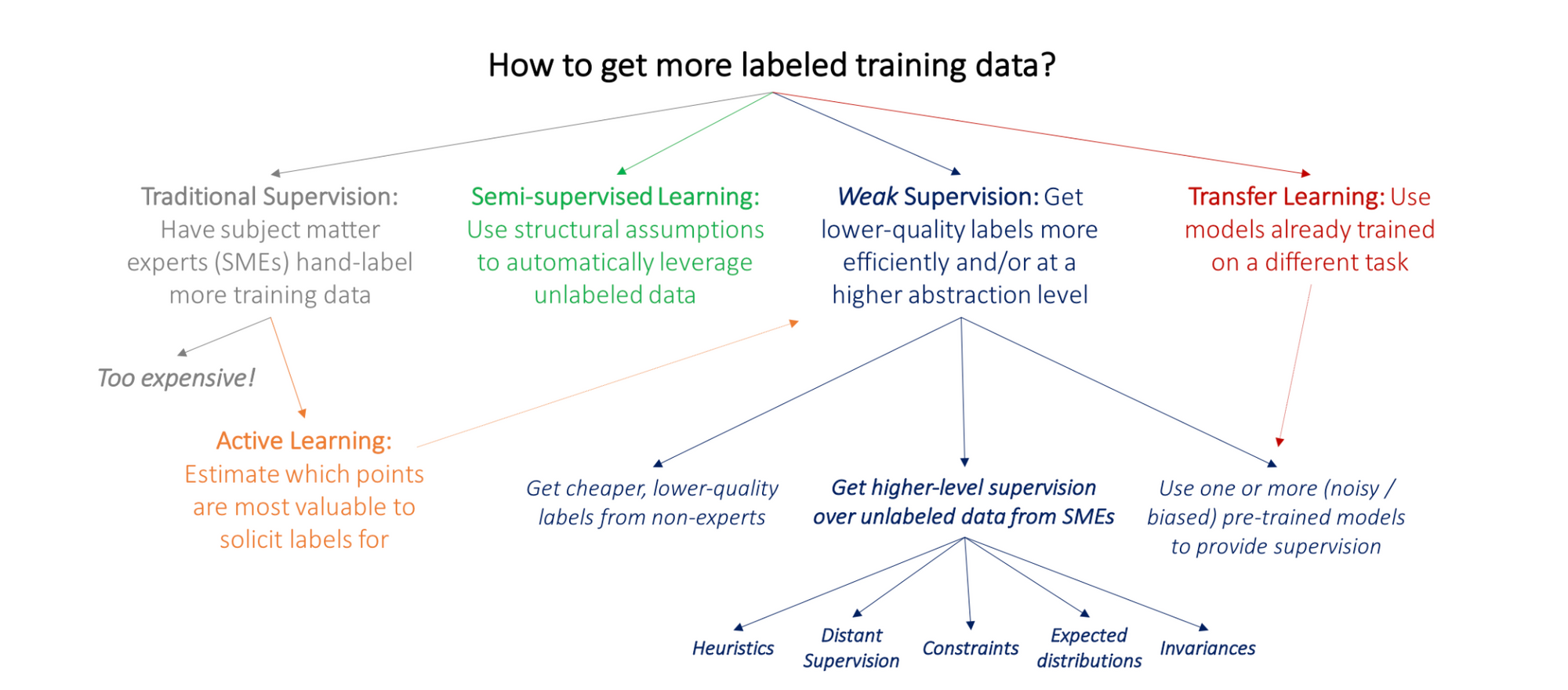
A number of strategies exist if data is limited: Active learning aims to utilize subject matter experts efficiently by having them label the data points deemed most valuable to the model. In a semi-supervised learning setting, a small labeled training set is combined with a larger unlabeled dataset to maximize data utilization. Transfer learning involves taking pre-trained models and applying them to a new dataset and task, allowing organizations to benefit from existing models. Additionally, the 2014 breakthrough of Generative Adversarial Networks (GANs) offers a means to generate authentic-looking images, which can help improve datasets with limited samples. Lastly, weakly supervised learning algorithms are designed to learn effectively from such imperfect labels by leveraging various techniques, such as incorporating domain knowledge, exploiting the structure of the data, or employing robust learning methods to handle the uncertainty in the labels.
Building a successful Data Flywheel
The concept of the flywheel, popularized by author Jim Collins, refers to a self-reinforcing loop of key initiatives that drive long-term business success. When applied to data collection and utilization, a Data Flywheel can create a self-sustaining momentum for data-driven growth. The Data Flywheel is propelled by many components acting in concert, amounting to a whole that is greater than the sum of its parts. To enable this, we need to establish a high-level flow of data from web apps, data logging systems, tools, services, and processes to our data warehouse, and ultimately facilitate the consumption of data for data-driven features or apps in an end-to-end manner.
Key steps in Building a Data Flywheel:
- Move data and workloads to the cloud for easier management and scalability.
- Run fully-managed databases to store all the data securely and efficiently.
- Build a centralized data lake to analyze data and feed it into data-driven apps or solutions.
- Continuously redeploy data-driven solutions to generate more data, fueling the flywheel and building momentum.

As the Data Flywheel gains momentum, organizations can derive accurate and timely insights that drive smarter decisions. This self-sustaining momentum has been effectively employed by internet companies, which have recognized that increased product usage leads to more data, smarter products, and ultimately, a data network effect. The Data Flywheel not only improves user experience but also serves to fortify a company’s competitive moat. Building a successful Data Flywheel can significantly enhance an organization’s data collection and utilization efforts. By developing an end-to-end data flow and continuously redeploying data-driven solutions, businesses can create self-sustaining momentum, driving smarter decisions and strengthening their competitive position in the market.
In summary, many AI projects are essentially machine learning projects, where we first need to ensure that there is sufficient data available, assess our ability to maintain data quality, and ensure that data samples are accurate reflections of the ML task being modeled. This means we must select data that is representative of the cases we want to generalize to and that contains the relevant features needed to learn the desired task. There are exceptions, such as scenarios where we can rely on techniques like transfer learning. By taking the time to develop each component and implement the most relevant procedures at every stage, organizations can establish a solid competitive edge. The key takeaway is that most AI projects can reduce the risk of failure if technical leadership takes the time to ensure that data availability, infrastructure, and quality requirements are met before execution begins.